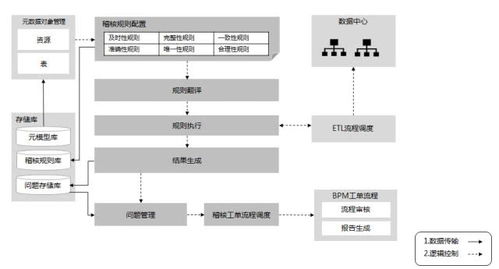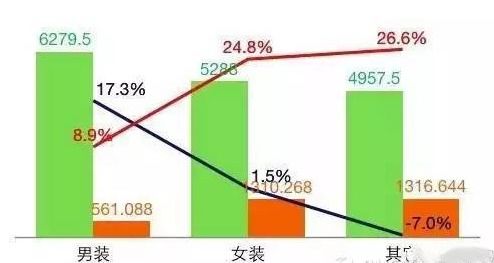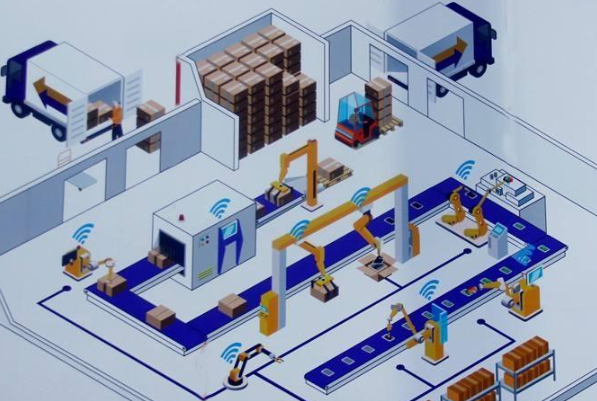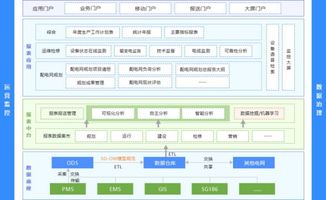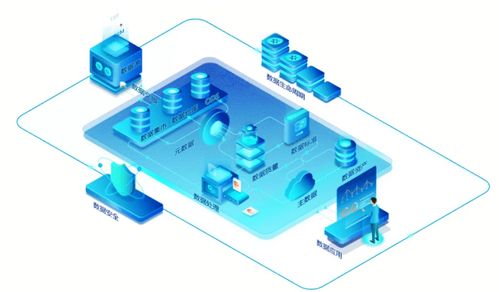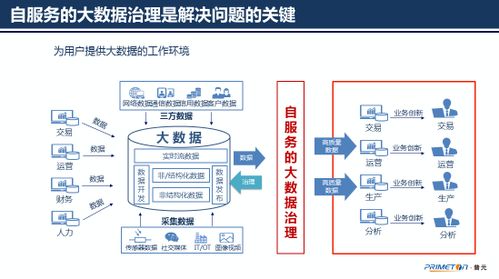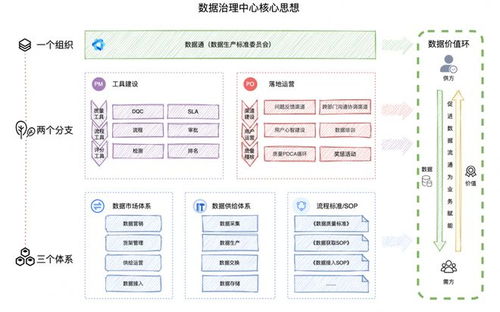
在當今數(shù)據(jù)驅(qū)動的商業(yè)環(huán)境中,數(shù)據(jù)分析已成為企業(yè)決策的核心。而數(shù)據(jù)分析的起點與質(zhì)量,很大程度上取決于其數(shù)據(jù)來源與處理方式。本文將深入解析數(shù)據(jù)分析中的兩個關(guān)鍵概念:接口數(shù)據(jù)源與數(shù)據(jù)處理服務(wù),闡明它們是什么、如何工作以及為何至關(guān)重要。
一、 接口數(shù)據(jù)源:數(shù)據(jù)的“高速公路”入口
1. 核心定義
接口數(shù)據(jù)源,簡而言之,是數(shù)據(jù)分析系統(tǒng)通過標準化協(xié)議(如API、Web Service、JDBC/ODBC等)從外部系統(tǒng)實時或定期獲取數(shù)據(jù)的通道。它不是一個靜態(tài)的數(shù)據(jù)文件或數(shù)據(jù)庫表,而是一個動態(tài)的、程序化的數(shù)據(jù)接入點。
2. 主要類型與特點
API接口:目前最常見的形式,尤其是RESTful API和GraphQL。它允許系統(tǒng)通過HTTP請求(GET、POST等)從第三方服務(wù)(如社交媒體平臺、支付網(wǎng)關(guān)、SaaS應(yīng)用)直接拉取結(jié)構(gòu)化數(shù)據(jù)(通常是JSON或XML格式)。特點是靈活、實時性強,但通常有調(diào)用頻率限制。
數(shù)據(jù)庫接口:通過JDBC、ODBC等標準協(xié)議直接連接業(yè)務(wù)數(shù)據(jù)庫(如MySQL、Oracle、SQL Server)。適用于需要分析企業(yè)內(nèi)部核心業(yè)務(wù)數(shù)據(jù)的場景,數(shù)據(jù)量大且結(jié)構(gòu)穩(wěn)定。
消息隊列接口:如Kafka、RabbitMQ等。用于接收實時流數(shù)據(jù),適用于監(jiān)控、日志分析、實時風控等對時效性要求極高的場景。
文件傳輸接口:通過FTP、SFTP或云存儲服務(wù)(如AWS S3、阿里云OSS)的API獲取批量數(shù)據(jù)文件(如CSV、Parquet)。
3. 在數(shù)據(jù)分析中的作用
接口數(shù)據(jù)源打破了數(shù)據(jù)孤島,使得分析系統(tǒng)能夠:
- 集成多源數(shù)據(jù):將來自CRM、ERP、網(wǎng)站、App、物聯(lián)網(wǎng)設(shè)備等不同來源的數(shù)據(jù)匯聚一堂。
- 獲取實時數(shù)據(jù):支持對實時業(yè)務(wù)指標(如在線交易額、用戶活躍度)進行監(jiān)控與分析。
- 自動化數(shù)據(jù)攝入:替代傳統(tǒng)手動導出/導入,實現(xiàn)數(shù)據(jù)流程的自動化與可重復性。
二、 數(shù)據(jù)處理服務(wù):數(shù)據(jù)的“煉油廠”
1. 核心定義
數(shù)據(jù)處理服務(wù)是一系列用于對原始數(shù)據(jù)(特別是從接口獲取的數(shù)據(jù))進行加工、轉(zhuǎn)換、清洗和組織的工具、平臺或代碼流程的總稱。它的目的是將雜亂、原始的“原油”數(shù)據(jù),提煉成干凈、統(tǒng)一、適合分析的“成品油”數(shù)據(jù)。
2. 關(guān)鍵處理環(huán)節(jié)
一個完整的數(shù)據(jù)處理服務(wù)通常包含以下環(huán)節(jié):
- 數(shù)據(jù)抽取:從接口數(shù)據(jù)源等地方拉取數(shù)據(jù)。
- 數(shù)據(jù)清洗:處理缺失值、異常值、格式不一致、重復記錄等問題。
- 數(shù)據(jù)轉(zhuǎn)換:進行格式轉(zhuǎn)換(如時間戳標準化)、字段計算、數(shù)據(jù)聚合、維度退化等。
- 數(shù)據(jù)加載:將處理后的數(shù)據(jù)寫入目標存儲,如數(shù)據(jù)倉庫(如Snowflake、BigQuery)、數(shù)據(jù)湖或分析數(shù)據(jù)庫。這個過程常被稱為 ETL 或 ELT。
3. 常見形態(tài)
可視化ETL/ELT工具:如Apache NiFi、Talend、Informatica、阿里的DataWorks等,提供圖形化界面配置數(shù)據(jù)處理流程。
代碼/腳本驅(qū)動:使用Python(Pandas、PySpark)、SQL或Scala(Spark)編寫數(shù)據(jù)處理腳本,靈活性最高。
云原生數(shù)據(jù)處理服務(wù):如AWS Glue、Azure Data Factory、Google Cloud Dataflow,提供全托管、可擴展的數(shù)據(jù)處理能力。
流處理引擎:如Apache Flink、Spark Streaming,專門用于處理實時接口流入的數(shù)據(jù)流。
三、 協(xié)同工作流:從接口到洞察
在實際的數(shù)據(jù)分析項目中,接口數(shù)據(jù)源與數(shù)據(jù)處理服務(wù)緊密協(xié)作,形成一個高效的數(shù)據(jù)流水線:
- 觸發(fā)與拉取:調(diào)度系統(tǒng)(如Airflow)或?qū)崟r監(jiān)聽器觸發(fā)任務(wù),通過預定義的接口向目標系統(tǒng)請求數(shù)據(jù)。
- 原始數(shù)據(jù)落地:獲取的原始數(shù)據(jù)通常先被持久化到“數(shù)據(jù)湖”或暫存區(qū),保留原始快照以備審計和重處理。
- 加工處理:數(shù)據(jù)處理服務(wù)啟動,對原始數(shù)據(jù)進行清洗、轉(zhuǎn)換、關(guān)聯(lián)和聚合,使其符合分析模型的要求。
- 服務(wù)與存儲:處理后的高質(zhì)量數(shù)據(jù)被加載到數(shù)據(jù)倉庫或數(shù)據(jù)集市,結(jié)構(gòu)化為易于查詢的星型/雪花模型。
- 分析與應(yīng)用:BI工具(如Tableau、FineBI)、數(shù)據(jù)應(yīng)用或AI模型從處理后的數(shù)據(jù)中獲取洞察,驅(qū)動決策。
四、 關(guān)鍵考量與最佳實踐
- 穩(wěn)定性與監(jiān)控:接口可能不穩(wěn)定或變更,數(shù)據(jù)處理流程可能失敗。必須建立完善的日志、監(jiān)控和告警機制。
- 數(shù)據(jù)質(zhì)量:在數(shù)據(jù)處理階段建立數(shù)據(jù)質(zhì)量校驗規(guī)則(如唯一性、非空、值域檢查),從源頭保障分析結(jié)果的可靠性。
- 性能與成本:接口調(diào)用頻次、數(shù)據(jù)量大小直接影響處理速度和云服務(wù)成本。需要優(yōu)化調(diào)度策略和處理邏輯。
- 安全與合規(guī):接口認證(API Key、OAuth)、數(shù)據(jù)傳輸加密、敏感數(shù)據(jù)脫敏是必須遵守的安全底線。
###
接口數(shù)據(jù)源是數(shù)據(jù)分析的“源頭活水”,決定了你能獲得什么樣的原材料;而數(shù)據(jù)處理服務(wù)是核心的“加工引擎”,決定了原材料的品質(zhì)和可用性。理解并熟練運用這兩者,是構(gòu)建可靠、高效、可擴展的數(shù)據(jù)分析體系的基礎(chǔ)。在現(xiàn)代數(shù)據(jù)架構(gòu)中,它們正朝著實時化、自動化、智能化的方向不斷演進,持續(xù)賦能數(shù)據(jù)價值的高效釋放。